

Machine learning is revolutionizing technology, and the K Nearest Neighbors Algorithm stands at the forefront of this exciting transformation. Understanding this powerful technique can unlock new possibilities in data analysis.
K Nearest Neighbors Algorithm is a smart machine learning approach that leverages proximity to predict or classify data points by examining its closest neighbors in the dataset.
As we dive deeper into this fascinating algorithm, you’ll discover how KNN can transform complex data into meaningful insights, making advanced technology more accessible and understandable for everyone.
Table of Contents
- What is the K Nearest Neighbors Algorithm?
- Why do we need a KNN algorithm?
- How does KNN Actually Work?
- Distance Metrics Used in KNN Algorithm
- How to Select the Value of K in the K-NN Algorithm?
- Types of Problems KNN Solves
- Advantages and Disadvantages of KNN
- Limitations of KNN
- Conclusion
What is the K Nearest Neighbors Algorithm?
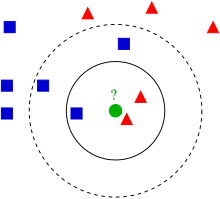
The K Nearest Neighbors (KNN) Algorithm is like a friendly detective in the world of data. Imagine you want to predict something about a new data point by looking at its closest neighbors.
KNN does exactly that! It examines the nearest known data points and uses their characteristics to make a smart guess about the unknown point.
Think of it like finding the best restaurant recommendation. If your friends who like similar food recommend a place, you’re likely to enjoy it too.
KNN works similarly, using proximity and similarity to make predictions or classifications in various fields like finance, healthcare, and technology.
This algorithm is wonderfully simple yet powerful, making complex data analysis feel like solving a fun puzzle with your closest friends.
Why do we need a KNN algorithm?
In today’s data-driven world, we constantly need smart ways to understand and predict patterns. The KNN algorithm becomes our problem-solving superhero in this scenario.
It helps us make sense of complex information by finding similarities and making educated guesses about unknown data points.
Consider real-world scenarios where KNN shines:
- Recommending products you might like based on similar customer preferences
- Detecting potential health risks by comparing medical data
- Predicting house prices by analyzing similar neighborhood properties
- Identifying spam emails by comparing them with known spam patterns
KNN’s beauty lies in its simplicity. It doesn’t require complex mathematical training and can adapt quickly to different types of problems.
Whether you’re a business, researcher, or curious learner, KNN offers an intuitive way to extract meaningful insights from data.
By looking at its closest neighbors, the algorithm helps us answer crucial questions: “What’s likely to happen next?” and “What does this data point probably represent?”.
How does KNN Actually Work?
Imagine KNN as a friendly neighborhood detective solving mysteries about new data points. The algorithm works by finding the closest “neighbors” to an unknown data point and making predictions based on their characteristics.
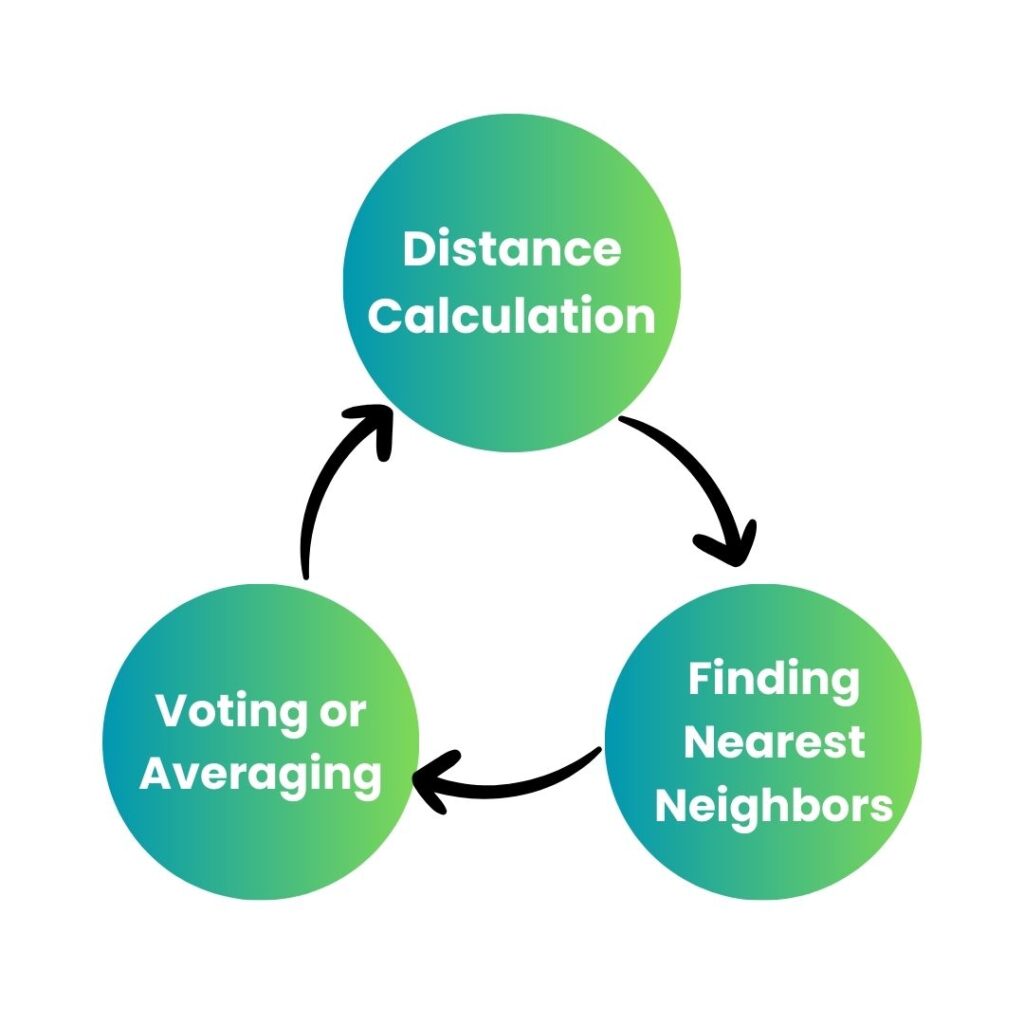
Here’s a step-by-step breakdown:
First Step: Distance Calculation
When a new data point arrives, KNN first calculates its distance from all existing data points. Think of this like measuring how close different houses are to each other on a street. The most common way to measure this distance is using Euclidean distance, which is like drawing a straight line between two points.
Second Step: Finding Nearest Neighbors
After calculating distances, KNN selects the ‘K’ closest data points. If K is 3, it will look at the three nearest neighbors. This is similar to asking your three closest friends for advice about a decision.
Third Step: Voting or Averaging
For classification problems, these neighbors “vote” on the label of the new point. In regression problems, KNN takes the average of the neighbors’ values. It’s like deciding a restaurant’s rating by asking multiple friends who’ve been there.
Example Scenario:
Let’s say you want to predict whether a new fruit is an apple or an orange. KNN would look at the color, size, and shape of the nearest known fruits and make a prediction based on the majority of those neighbors.
The magic of KNN is its simplicity: it uses proximity and similarity to make smart predictions across various fields like recommendation systems, medical diagnosis, and financial forecasting.
Distance Metrics Used in KNN Algorithm
Distance metrics are like measuring tape for data points. They help KNN understand how close or far different data points are from each other. Choosing the right distance metric is crucial for accurate predictions.
Common Distance Metrics:
Euclidean Distance
The most popular metric, it calculates the straight-line distance between two points. Imagine drawing a direct line between two spots on a map. It works best for continuous numerical data like height, weight, or temperature.
Manhattan Distance
Also called city block distance, it measures distance like walking city streets. Instead of a straight line, it calculates the total horizontal and vertical distance. Think of navigating city blocks to reach a destination.
Hamming Distance
Perfect for categorical or binary data. It counts the number of positions where two data points differ. Used in scenarios like comparing genetic sequences or detecting errors in data transmission.
Cosine Distance
Measures the angle between two data points, ignoring their magnitude. Particularly useful in text analysis and recommendation systems, where the direction of data matters more than its absolute size.
Practical Tip:
The distance metric choice depends on your problem and data type. Experimenting with different metrics can help improve your KNN model’s accuracy.
How to Select the Value of K in the K-NN Algorithm?
Choosing the right K value is like finding the perfect recipe balance – too little or too much can ruin the entire dish. The K value determines how many neighbors the algorithm will consider when making predictions.
Selection Strategies
Here are the selection strategies:
1. Odd Number Rule
Always choose an odd number for K to avoid tie-breaking issues in classification problems. This ensures a clear majority when voting for a class.
2. Square Root Method
A simple trick is to set K as the square root of the total number of data points. For 100 data points, K would be around 10.
3. Cross-Validation
The most reliable method involves testing different K values and checking which provides the most accurate results. This is like trying multiple cooking techniques to find the best one.
Common K Value Scenarios:
- Small K (1-3): Very sensitive to noise, might lead to overfitting
- Medium K (5-10): Generally provides balanced results
- Large K (15-20): Smoother decision boundaries, but might miss important local patterns
Important Tip: There’s no universal “perfect” K value. The best approach is experimenting and finding what works best for your specific dataset.
Types of Problems KNN Solves
KNN is a versatile algorithm that tackles two primary problem types: classification and regression. Think of it as a multi-purpose tool in the machine learning toolkit.
Classification Problems
In classification, KNN helps categorize data into predefined groups. Examples include:
- Spam email detection
- Disease diagnosis
- Customer segmentation
- Handwriting recognition
Regression Problems
Here, KNN predicts continuous numeric values. Think of scenarios like:
- House price prediction
- Stock market forecasting
- Temperature estimation
- Product price recommendations
Real-World Application Examples:
- E-commerce: Recommending products based on similar customer preferences
- Healthcare: Predicting patient risk levels
- Finance: Estimating loan eligibility
- Agriculture: Predicting crop yields
Advantages and Disadvantages of KNN
There are some advantages are disadvantages of KNN. Let’s explore:
Advantages of KNN
Here are some advantages of KNN:
1. Simplicity
- Easy to understand and implement
- No complex training required
- Works well with small datasets
- Minimal parameter tuning
2. Flexibility
- Handles both classification and regression problems
- Works with multi-class classification
- Adapts quickly to new data
- No assumptions about underlying data distribution
3. No Training Phase
- Learns during prediction time
- Quick to start using
- Continuously updates with new information
Disadvantages of KNN
Here are the disadvantages of KNN:
1. Computational Complexity
- Slow with large datasets
- Requires calculating distance for every data point
- Memory-intensive
- Performance degrades as data grows
2. Sensitive to Irrelevant Features
- All features treated equally
- Needs careful feature selection
- Requires data normalization
- Prone to bias from irrelevant attributes
3. Curse of Dimensionality
- Struggles with high-dimensional data
- Distance calculations become less meaningful
- Performance drops dramatically
- Requires dimensionality reduction techniques
4. Choice of K Value
- Selecting optimal K can be challenging
- Different K values produce different results
- Requires cross-validation
- No universal K value works for all scenarios
Limitations of KNN
Here are hte limitations of KNN:
Performance Challenges
- High computational complexity with large datasets
- Inefficient for real-time prediction scenarios
- Significant memory requirements
- Processing speed decreases exponentially with data volume
Data Sensitivity Issues
- Extremely vulnerable to irrelevant features
- Poor performance in high-dimensional spaces
- Requires extensive data preprocessing
- Inconsistent results with imbalanced datasets
Decision-Making Constraints
- No explicit training phase
- Dependent on distance calculation methods
- Highly influenced by chosen distance metric
- Limited interpretability of model decisions
Scalability Problems
- Linear increase in computation time
- Not suitable for big data environments
- Struggles with streaming or dynamic datasets
- Requires complete dataset in memory
Feature Impact
- Equal weightage to all features
- No automatic feature selection mechanism
- Needs manual feature engineering
- Sensitive to data normalization techniques
Critical Considerations
- Not ideal for complex, non-linear relationships
- Performance degrades with increased dimensionality
- Requires careful parameter tuning
- Prone to overfitting with small K values
Conclusion
In conclusion, the K Nearest Neighbors Algorithm offers a powerful, intuitive approach to solving complex data problems. By understanding its mechanics, strengths, and limitations, data enthusiasts can leverage KNN effectively across various domains. This versatile algorithm continues to be a valuable tool in machine learning, helping us transform raw data into meaningful insights with remarkable simplicity and elegance.