

Ever wondered why some machine learning models work great, while others fail? It often comes down to how well they fit the data. Let’s explore this important concept.
The difference between overfitting and underfitting is crucial in machine learning. Overfitting happens when a model learns too much from training data, while underfitting occurs when it learns too little.
In this blog, we’ll dive into the difference between overfitting and underfitting. We’ll use simple examples to help you understand these ideas and show you how to spot them in your own projects.
Table of Contents
- What is Fitting in Machine Learning?
- What is Overfitting?
- What is Underfitting?
- Difference Between Overfitting and Underfitting
- How to Spot Overfitting and Underfitting
- Conclusion
What is Fitting in Machine Learning?
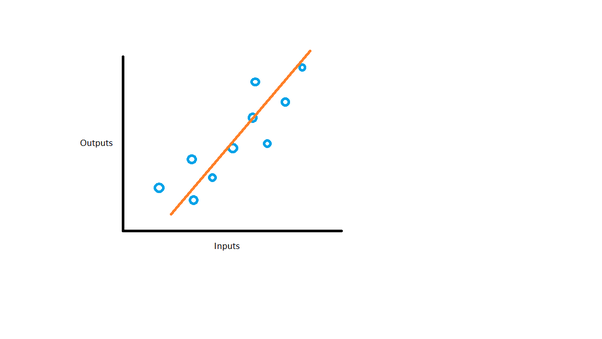
Fitting in machine learning is all about how well a model learns from data. Think of it like trying on shoes. You want a pair that fits just right – not too tight, not too loose.
In machine learning, we want our model to fit the data well. This means it should be able to understand the patterns in the data it’s trained on.
A good fit helps the model make accurate predictions on new, unseen data. It’s like wearing comfortable shoes that work well for different activities.
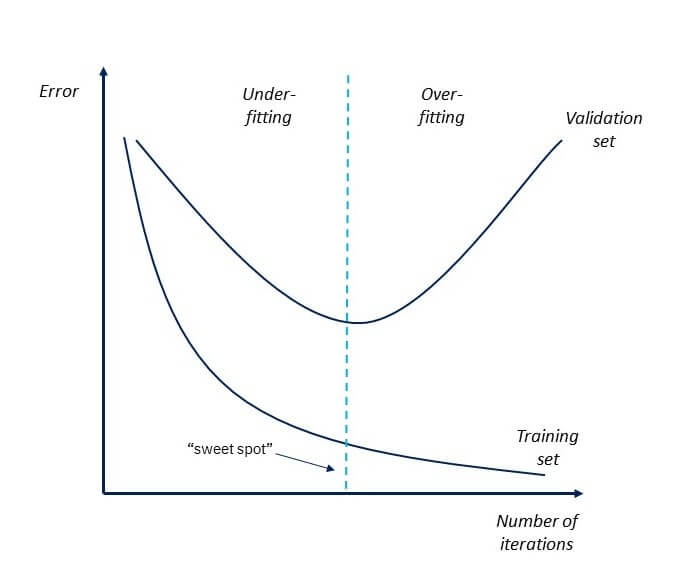
The goal is to find the sweet spot. We want our model to learn enough to be useful, but not so much that it can’t handle new situations.
What is Overfitting?
Overfitting happens when a machine learning model tries too hard to learn. It’s like memorizing every detail in a textbook, even the typos!
When a model overfits, it performs great on the data it was trained on. But it struggles with new, unseen data. It’s like knowing everything about your hometown but getting lost in a new city.
Imagine a student who only studies past exam papers. They might ace a test with similar questions but fail if the questions are different. That’s overfitting in action.
Overfitting models are too complex. They learn noise and random fluctuations in the training data, mistaking them for important patterns.
What is Underfitting?
Underfitting is the opposite of overfitting. It happens when a machine learning model doesn’t learn enough from the data. Think of it as skimming a book instead of reading it properly.
When a model under-fits, it performs poorly on both the training data and new data. It’s like trying to understand a complex topic by only reading the chapter titles.
Imagine a student who only learns basic addition. They’d struggle with any math problem involving multiplication or division. That’s underfitting in action.
Underfitting models are too simple. They miss important patterns in the data and make overly general assumptions. It’s like using a straight line to describe a curved relationship.
Difference Between Overfitting and Underfitting
Understanding the difference between overfitting and underfitting is key to building good machine-learning models. Let’s break it down in simple terms:
| Aspect | Overfitting | Underfitting |
| Learning | Learns too much, including data noise | Learns too little, misses important patterns |
| Model complexity | Too complex for the data | Too simple to capture data patterns |
| Training data performance | Extremely good | Poor |
| New data performance | Poor | Poor |
| Flexibility | Too flexible, fits every data point | Too rigid, doesn’t fit data well |
| Real-world example | Memorizing a textbook word-for-word | Only reading chapter summaries |
Think of overfitting as being too specific, like remembering every tiny detail of your hometown but getting lost everywhere else. Underfitting is like only knowing major landmarks – you’ll struggle to navigate anywhere, even at home.
The goal is to find a sweet spot between these two. A good model should learn enough to be useful but not so much that it can’t handle new situations.
How to Spot Overfitting and Underfitting
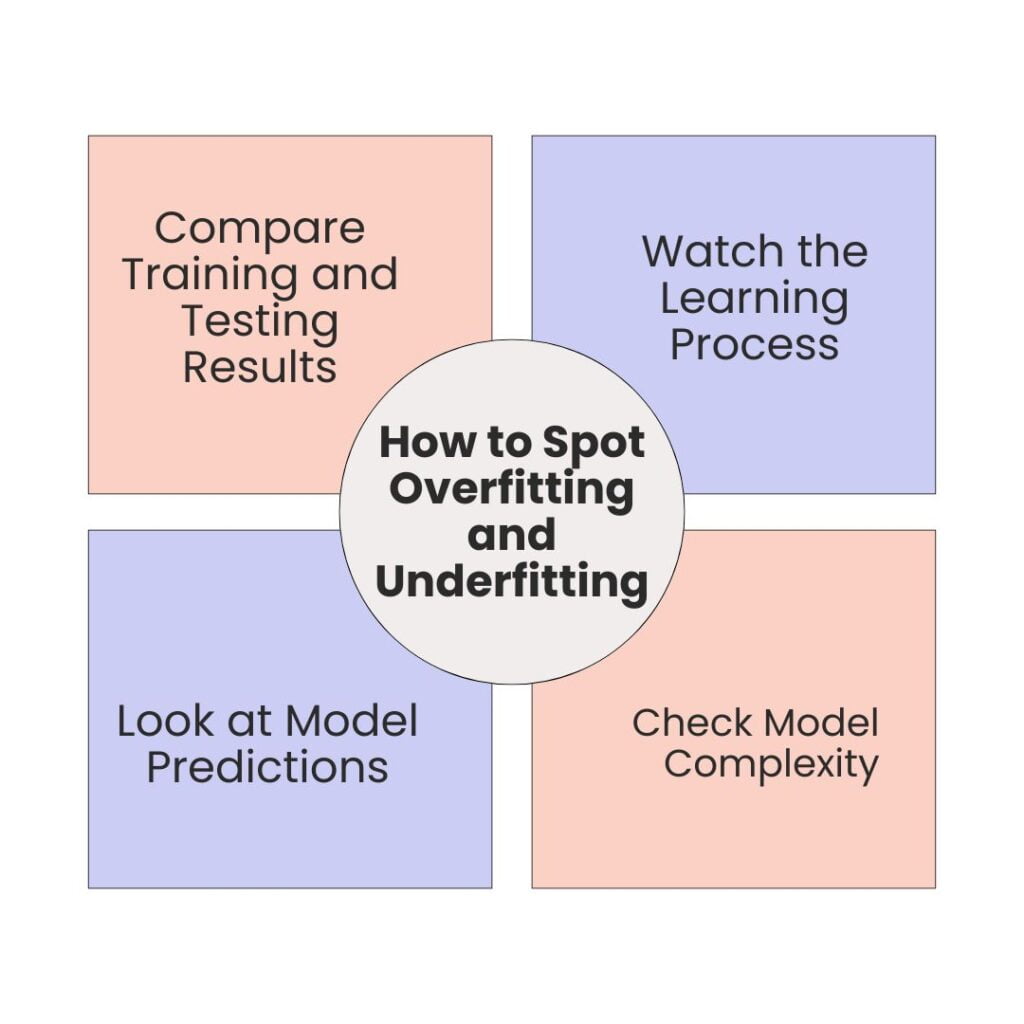
Knowing how to spot overfitting and underfitting is key to building good machine-learning models. Here’s a simple way to identify these issues:
1. Compare Training and Testing Results
When you train your model, split your data into two parts: training data and testing data. Then, look at how your model performs on both:
- If your model does great on training data but poorly on testing data, it’s probably overfitting.
- If it does poorly on both training and testing data, it’s likely underfitting.
2. Watch the Learning Process
As your model learns, keep an eye on its progress:
- In overfitting, the model keeps getting better with training data but starts doing worse with new data.
- In underfitting, the model doesn’t improve much with either training or new data.
3. Look at Model Predictions
Pay attention to how your model makes predictions:
- An overfitting model might make very specific predictions, like guessing a house price based on its exact address.
- An underfitting model makes too general predictions, like guessing house prices based only on the city.
4. Check Model Complexity
Think about how complex your model is:
- Overfitting often happens with very complex models that try to account for every little detail.
- Underfitting usually occurs with too simple models that miss important patterns.
Remember, the goal is to find a balance. A good model should work well with both familiar and new data, catching important patterns without getting thrown off by small details.
Conclusion
In conclusion, understanding the difference between overfitting and underfitting is crucial for building effective machine-learning models. Overfitting happens when a model learns too much from training data, while underfitting occurs when it learns too little. Striking the right balance is key. By spotting these issues early, you can adjust your model to perform well on both familiar and new data, leading to more accurate and useful predictions.